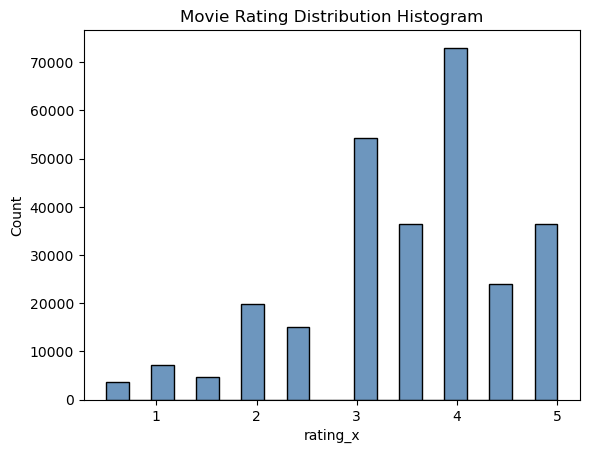
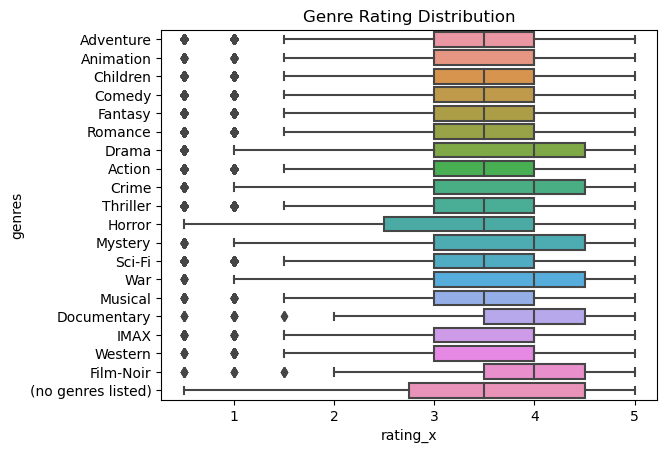
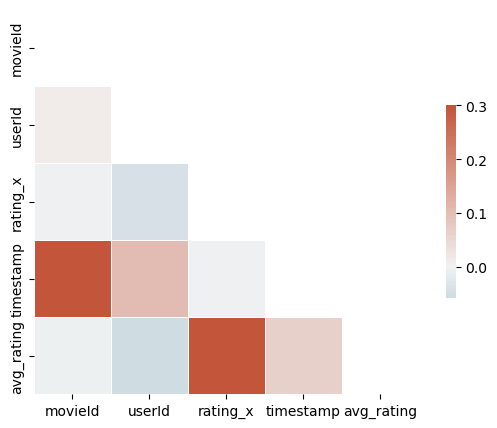
Code
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#Data import
movie_ratings_df = pd.read_csv('../data-cleaning/ml-latest-small/movie_ratings_cleaned.csv')
print(movie_ratings_df.head())
#Saving number of rows and columns
num_rows=len(movie_ratings_df.index)
num_cols=len(movie_ratings_df.columns)
print("Nrows = ",num_rows,"\nNcol=",num_cols,"\nMatrix entries = ", num_rows*num_cols)
keys = movie_ratings_df.columns
keys_dtype = movie_ratings_df.dtypes
print('--------------------')
print('GENERAL INFORMATION:')
print('--------------------')
print(f'number of rows: {num_rows}')
print(f'number of col: {num_cols}')
print(f'keys: {keys} {keys_dtype}') movieId title genres userId rating_x timestamp \
0 1 Toy Story (1995) Adventure 1 4.0 964982703
1 1 Toy Story (1995) Animation 1 4.0 964982703
2 1 Toy Story (1995) Children 1 4.0 964982703
3 1 Toy Story (1995) Comedy 1 4.0 964982703
4 1 Toy Story (1995) Fantasy 1 4.0 964982703
avg_rating
0 3.92093
1 3.92093
2 3.92093
3 3.92093
4 3.92093
Nrows = 274480
Ncol= 7
Matrix entries = 1921360
--------------------
GENERAL INFORMATION:
--------------------
number of rows: 274480
number of col: 7
keys: Index(['movieId', 'title', 'genres', 'userId', 'rating_x', 'timestamp',
'avg_rating'],
dtype='object') movieId int64
title object
genres object
userId int64
rating_x float64
timestamp int64
avg_rating float64
dtype: object